草稿阶段,持续更新!!!
本系列文章的目的
- cva6文档甚少,依靠源码与仿真工具学习效率低;
- 个人学习总结记录;
- 希望可以找到一同交流学习的小伙伴,对cva6进行改进,改善它的IPC。
注:本文仅是个人感悟梳理,细节内容需要自行查阅源码、《计算机组成与设计-硬件/软件接口》、《计算机体系结构-量化研究方法》、相关wiki博客,方可领悟CPU体系结构的精髓,本文仅是小小的总结而已,内容较为单薄!
cva6简介
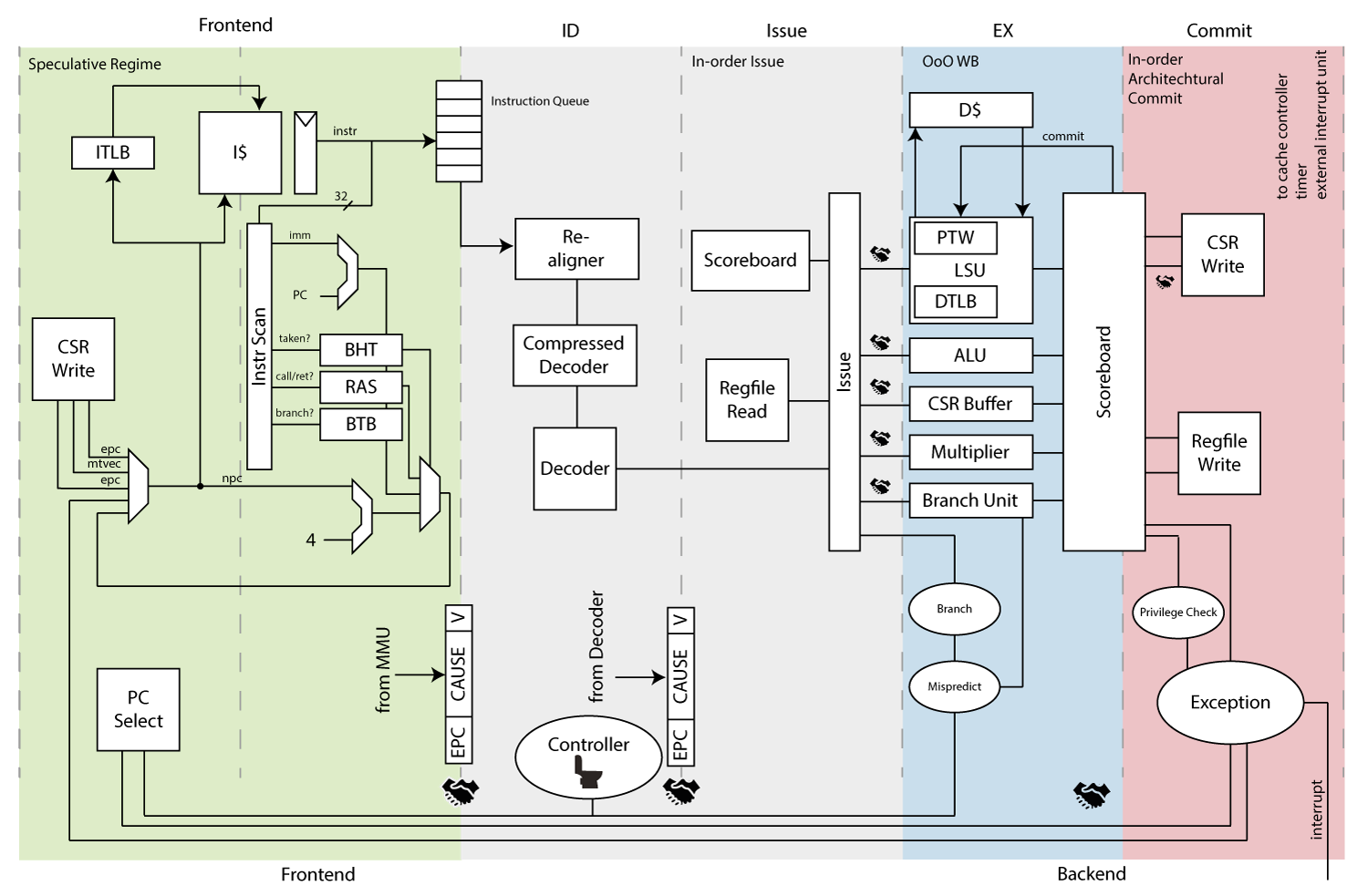
cva6是一颗具备6级流水、单发射、顺序执行的64bit RISC-V CPU,不仅实现了RV64IMAFDC(RV64GC)指令,也实现了RISC-V三种特权等级,因此具备运行类Unix系统的能力。
注:目前官方的图没有更新到最新的主线,有细微的差别。
cva6特性概览
- RV64GC
- 实现了RV64IMAFDC,即支持整数指令I、整数乘除M、单精度浮点F、双精度浮点D、原子指令A、压缩指令C。一个可以运行的RISC-V处理器仅支持整数指令集I即可,其他均为可选的模块。
- 6级流水
- 6个流水阶段主要划分为PC Generation—PC生成阶段、Instruction Fetch—指令获取阶段、Instruction Decode—指令译码阶段、Issue—指令发射阶段、Execute—指令执行阶段、Commit—指令提交阶段。
- 流水线的动态调度
- Scoreboard:计分板技术,起源于1965年交付的CDC6000,记录并避免WAW、WAR、RAW数据依赖性,通过动态调度流水线的方式,实现乱序执行,提高流水线效率;
- Register renaming:寄存器重命名,解决数据依赖性问题,支持乱序执行,但cva6暂未完全实现。
- 动态分支预测
- BTB:branch target buffer;
- BHT:branch history table 基于2bit饱和计数器;
- RAS:return address stack。
- Linux Boot
- 实现了RISC-V的三种特权模式,分别是机器模式M-Machine Mode、监督模式S-Supervisor Mode、用户模式U-User Mode;
- 具备ITLB、DTLB、PTW实现虚拟地址到物理地址的快速翻译;
- 具备可灵活配置的4路组相连L1ICache与L1DCache。
- 官方基于22nm-FDSOI流片,运行频率可达1.7GHZ
- FPGA Emulation
- 官方支持在Digilent的Genesys 2、Xilinx的kc705、Xilinx的vc707板卡上运行cva6,并启动Linux;
- 在容量足够的情况下,其他板卡原则上也可以支持,不过需要少量的移植工作。
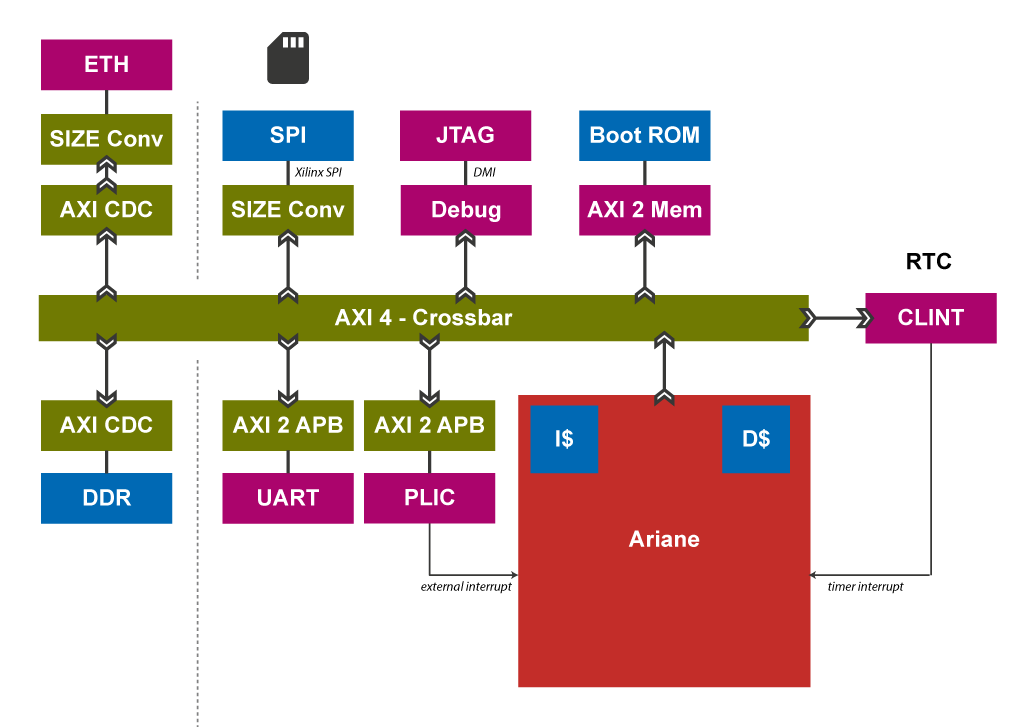
下图是基于cva6的SOC组成,可在FPGA上运行。
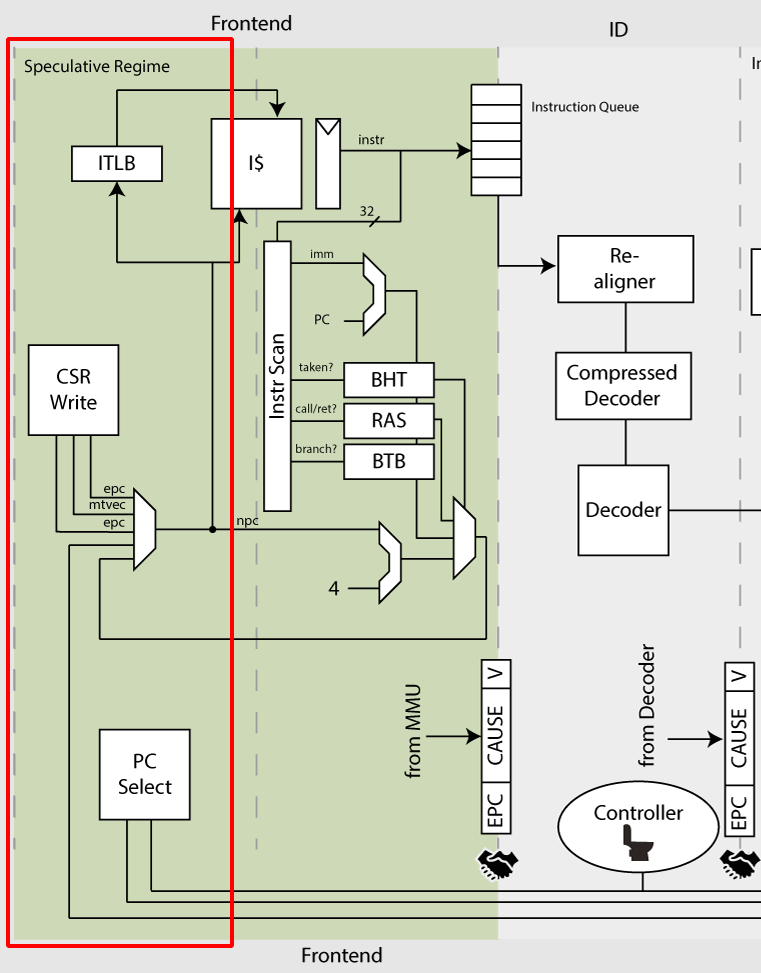
PC生成阶段-PC Generation
PC生成阶段是为了产生下一个将要获取指令的指针地址,PC值的来源主要有以下几个部分
- Branch Predict
- 通过当前的PC指针利用动态分支预测模块BHT与静态分支预测来判断是否跳转;
- 通过BTB来记录历史跳转地址。
- Default assignment
- 默认是PC + 4。
- replay
- 缓存分支预测地址的FIFO已满,暂停取指。
- Mis-prediction
- 分支预测错误,从执行阶段计算的地址开始取指。
- Return from environment call
- 遇到从环境调用中返回指令mret、sret、dret,则下个取指地址分别为CSR寄存器mepc、sepc、dpc中记录的数值。
- Exception/Interrupt
- 异常和中断导致的跳转,跳转地址依据特权等级以及mtvec、stvec等计算。
- Pipeline Flush because of CSR side effects
- 由于一些特殊的指令比如同步内存和I/O的fence指令会导致流水线刷新,从提交的指令地址 + 4 重新取指。
- Debug
- Debug放在组合逻辑赋值的最后,因此具有最高的权限,启动debug之后会进入一个硬编码的地址,cva6是
64'h800。
- Debug放在组合逻辑赋值的最后,因此具有最高的权限,启动debug之后会进入一个硬编码的地址,cva6是
具体来说PC生成阶段相关代码示例如下
// -------------------
// Next PC
// -------------------
// next PC (NPC) can come from (in order of precedence):
// 0. Default assignment/replay instruction
// 1. Branch Predict taken
// 2. Control flow change request (misprediction)
// 3. Return from environment call
// 4. Exception/Interrupt
// 5. Pipeline Flush because of CSR side effects
// Mis-predict handling is a little bit different
// select PC a.k.a PC Gen
always_comb begin : npc_select
automatic logic [riscv::VLEN-1:0] fetch_address;
// check whether we come out of reset
// this is a workaround. some tools have issues
// having boot_addr_i in the asynchronous
// reset assignment to npc_q, even though
// boot_addr_i will be assigned a constant
// on the top-level.
if (npc_rst_load_q) begin
npc_d = boot_addr_i;
fetch_address = boot_addr_i;
end else begin
fetch_address = npc_q;
// keep stable by default
npc_d = npc_q;
end
// 0. Branch Prediction
if (bp_valid) begin
fetch_address = predict_address;
npc_d = predict_address;
end
// 1. Default assignment
if (if_ready) npc_d = {fetch_address[riscv::VLEN-1:2], 2'b0} + 'h4;
// 2. Replay instruction fetch
if (replay) npc_d = replay_addr;
// 3. Control flow change request
if (is_mispredict) npc_d = resolved_branch_i.target_address;
// 4. Return from environment call
if (eret_i) npc_d = epc_i;
// 5. Exception/Interrupt
if (ex_valid_i) npc_d = trap_vector_base_i;
// 6. Pipeline Flush because of CSR side effects
// On a pipeline flush start fetching from the next address
// of the instruction in the commit stage
// we came here from a flush request of a CSR instruction or AMO,
// as CSR or AMO instructions do not exist in a compressed form
// we can unconditionally do PC + 4 here
// TODO(zarubaf) This adder can at least be merged with the one in the csr_regfile stage
if (set_pc_commit_i) npc_d = pc_commit_i + {{riscv::VLEN-3{1'b0}}, 3'b100};
// 7. Debug
// enter debug on a hard-coded base-address
if (set_debug_pc_i) npc_d = ArianeCfg.DmBaseAddress[riscv::VLEN-1:0] + dm::HaltAddress[riscv::VLEN-1:0];
icache_dreq_o.vaddr = fetch_address;
endPC生成阶段逻辑框图如下
cva6的分支预测是由动态分支预测与静态分支预测结合而成。
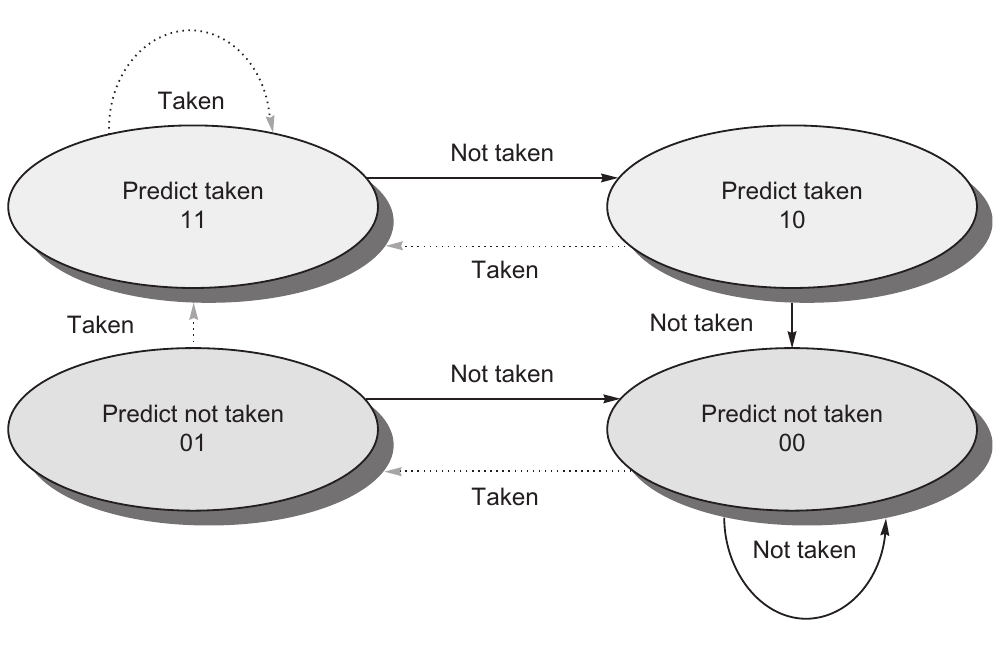
动态分支预测采用的是2bit饱和计数器(saturating counter)或者称双模态预测器(bimodal predictor),它是一种有4个状态的状态机:
- 强不选择(Strongly not taken)
- 弱不选择(Weakly not taken)
- 弱选择(Weakly taken)
- 强选择(Strongly taken)
2bit饱和计数器状态转移图如下
如下是具有4096-entry与infinite-entry的2bit饱和计数器的动态分支预测在SPEC89的Miss统计直方图,为节省逻辑资源cva6以分支预测准确率为代价,仅默认使用128-entry。
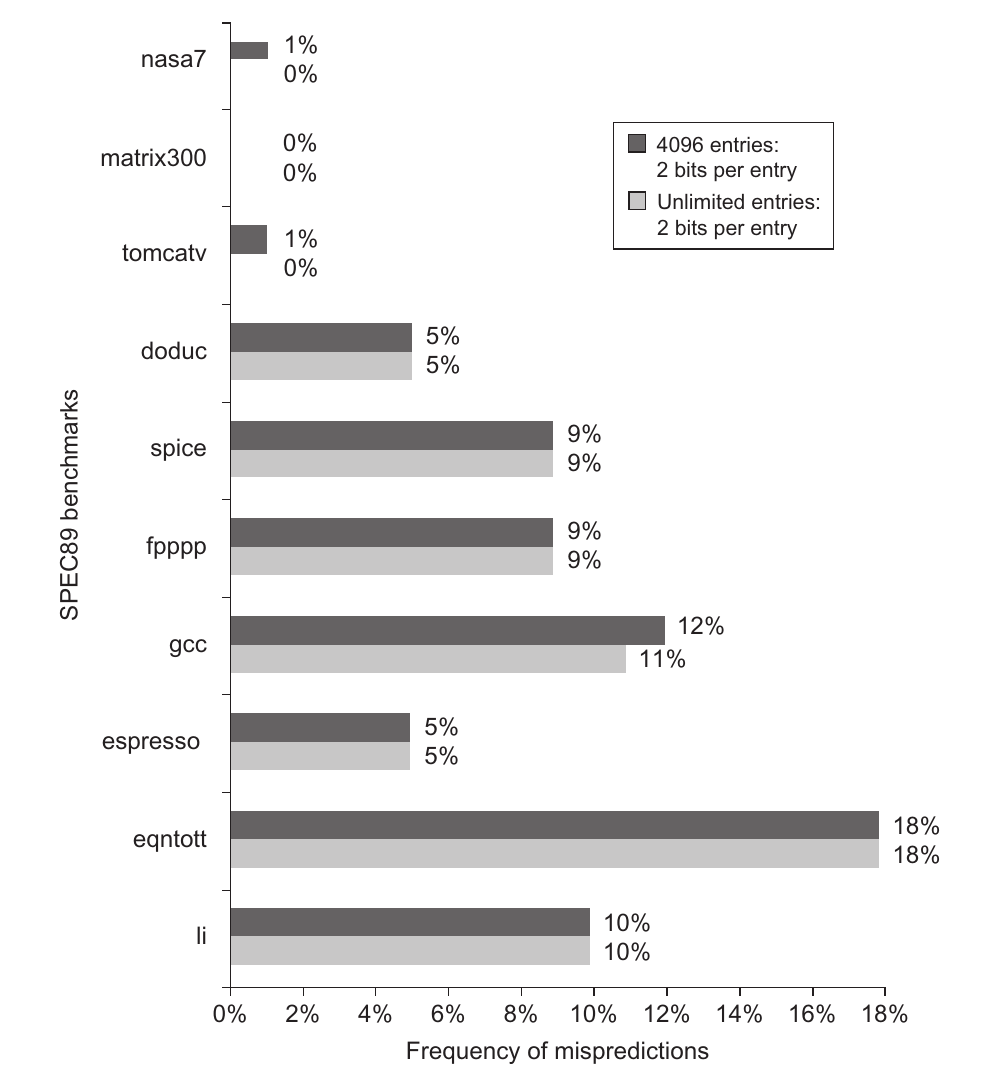
最初该分支预测方案在Intel Pentium处理器中使用。如此古老的动态分支预测的在现在看来稍微差些,但随后的动态分支预测改进不少是基于此的,因此作为学习模板足够了。更高级的分级预测方案有两级自适应预测器、局部分支预测、overriding分支预测、神经分支预测器等方案,进一步提高预测准确率。
当没有有效动态分支预测数据的时候,使用默认向前跳转的“静态分支预测”,如下是cva6分支预测部分代码。
always_comb begin
taken_rvi_cf = '0;
taken_rvc_cf = '0;
predict_address = '0;
for (int i = 0; i < INSTR_PER_FETCH; i++) cf_type[i] = ariane_pkg::NoCF;
ras_push = 1'b0;
ras_pop = 1'b0;
ras_update = '0;
// lower most prediction gets precedence
for (int i = INSTR_PER_FETCH - 1; i >= 0 ; i--) begin
unique case ({is_branch[i], is_return[i], is_jump[i], is_jalr[i]})
4'b0000:; // regular instruction e.g.: no branch
// unconditional jump to register, we need the BTB to resolve this
4'b0001: begin
ras_pop = 1'b0;
ras_push = 1'b0;
if (btb_prediction_shifted[i].valid) begin
predict_address = btb_prediction_shifted[i].target_address;
cf_type[i] = ariane_pkg::JumpR;
end
end
// its an unconditional jump to an immediate
4'b0010: begin
ras_pop = 1'b0;
ras_push = 1'b0;
taken_rvi_cf[i] = rvi_jump[i];
taken_rvc_cf[i] = rvc_jump[i];
cf_type[i] = ariane_pkg::Jump;
end
// return
4'b0100: begin
// make sure to only alter the RAS if we actually consumed the instruction
ras_pop = ras_predict.valid & instr_queue_consumed[i];
ras_push = 1'b0;
predict_address = ras_predict.ra;
cf_type[i] = ariane_pkg::Return;
end
// branch prediction
4'b1000: begin
ras_pop = 1'b0;
ras_push = 1'b0;
// if we have a valid dynamic prediction use it
if (bht_prediction_shifted[i].valid) begin
taken_rvi_cf[i] = rvi_branch[i] & bht_prediction_shifted[i].taken;
taken_rvc_cf[i] = rvc_branch[i] & bht_prediction_shifted[i].taken;
// otherwise default to static prediction
end else begin
// set if immediate is negative - static prediction
taken_rvi_cf[i] = rvi_branch[i] & rvi_imm[i][riscv::VLEN-1];
taken_rvc_cf[i] = rvc_branch[i] & rvc_imm[i][riscv::VLEN-1];
end
if (taken_rvi_cf[i] || taken_rvc_cf[i]) cf_type[i] = ariane_pkg::Branch;
end
default:;
// default: $error("Decoded more than one control flow");
endcase
// if this instruction, in addition, is a call, save the resulting address
// but only if we actually consumed the address
if (is_call[i]) begin
ras_push = instr_queue_consumed[i];
ras_update = addr[i] + (rvc_call[i] ? 2 : 4);
end
// calculate the jump target address
if (taken_rvc_cf[i] || taken_rvi_cf[i]) begin
predict_address = addr[i] + (taken_rvc_cf[i] ? rvc_imm[i] : rvi_imm[i]);
end
end
end
// or reduce struct
always_comb begin
bp_valid = 1'b0;
// BP cannot be valid if we have a return instruction and the RAS is not giving a valid address
// Check that we encountered a control flow and that for a return the RAS
// contains a valid prediction.
for (int i = 0; i < INSTR_PER_FETCH; i++) bp_valid |= ((cf_type[i] != NoCF & cf_type[i] != Return) | ((cf_type[i] == Return) & ras_predict.valid));
end指令获取阶段-Instruction Fetch
指令获取阶段涉及到一个相对复杂的主题,主要涉及到如下几个模块
- TLB: translation lookaside buffer,转换后备缓冲区;
- L1Icache:L1指令缓存;
- DRAM
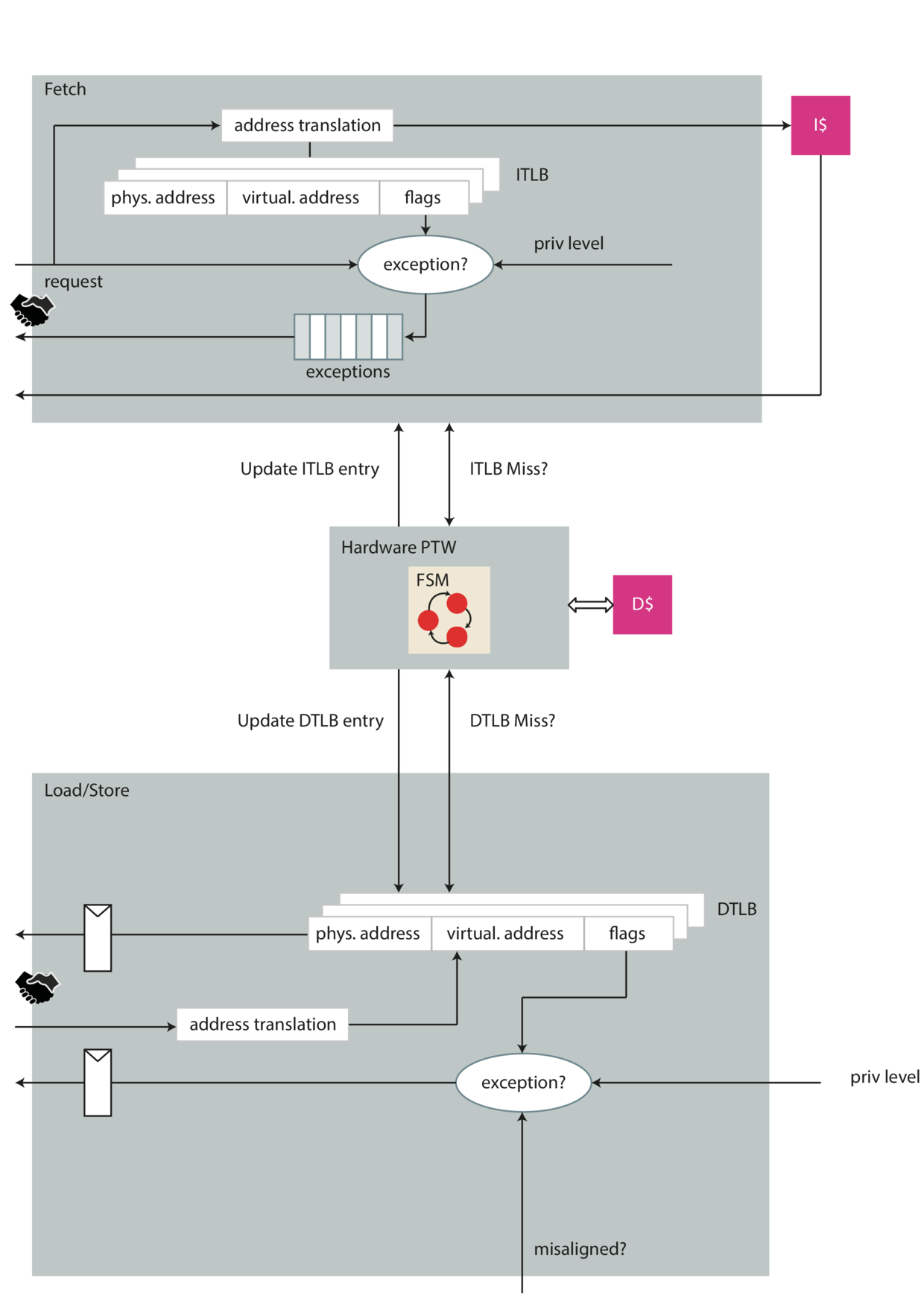
转换后备缓冲区-TLB
TLB与CSR寄存器中的satp - Supervisor Address Translation and Protection Register密切相关,字面意思该寄存器的主要功能是监管者地址转换和保护,控制分页系统。该寄存器的组成如下

下图示例是Sv32模式地址翻译流程
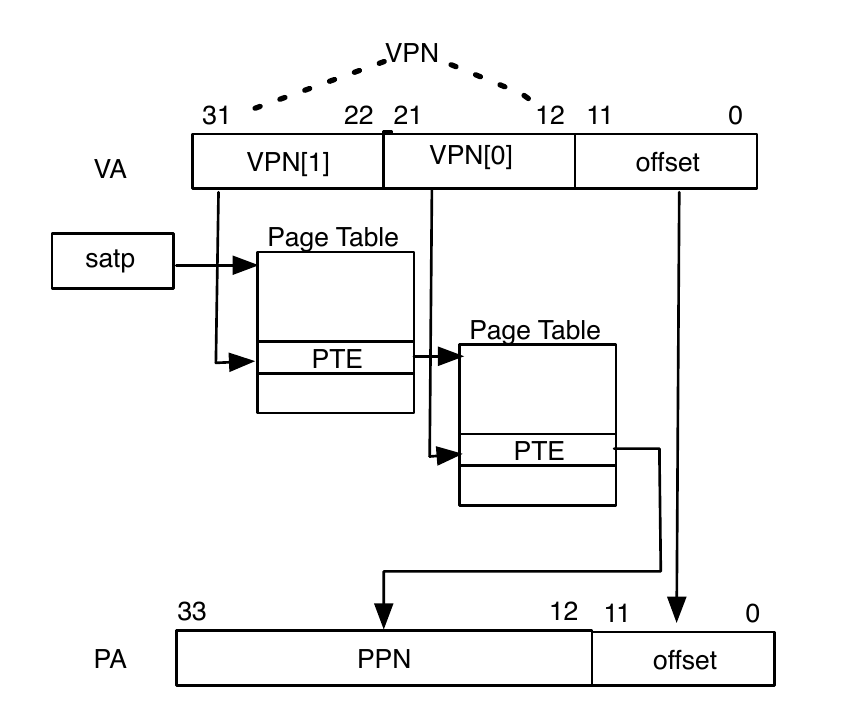
cva6默认采用的Sv39,与Sv32不同的是,其采用的是3级页表。Sv39 的 512GiB 地址空间划分为$2^9$个 GiB 大小的 gigapages, 每个 gigapages 被进一步划分为$2^9$个 megapages,每个 megapages 再进一步分为$2^9$个 4KiB 大小的 base pages。在Sv39中这些 gigapages 大小为 2 MiB,比 Sv32 中略小。
由于本部分较为复杂,而且测试程序默认屏蔽地址翻译,即PC的虚拟地址与物理地址相同,所以本部分暂且搁置,当做一个黑盒子来对待。
L1指令缓存-L1Icache
如对Cache不了解的小伙伴,可以移步查看这位博主的文章:Cache的基本原理。cva6核心部分仅具有L1Cache,为了提高流水线效率,L1Cache又分为ICache、DCache。L1ICache的默认配置是:
- cache size:16Kib
- cache lines:128bit
- Associativity:Four-way set
- Replacement policies:使用LFSR进行随机替换
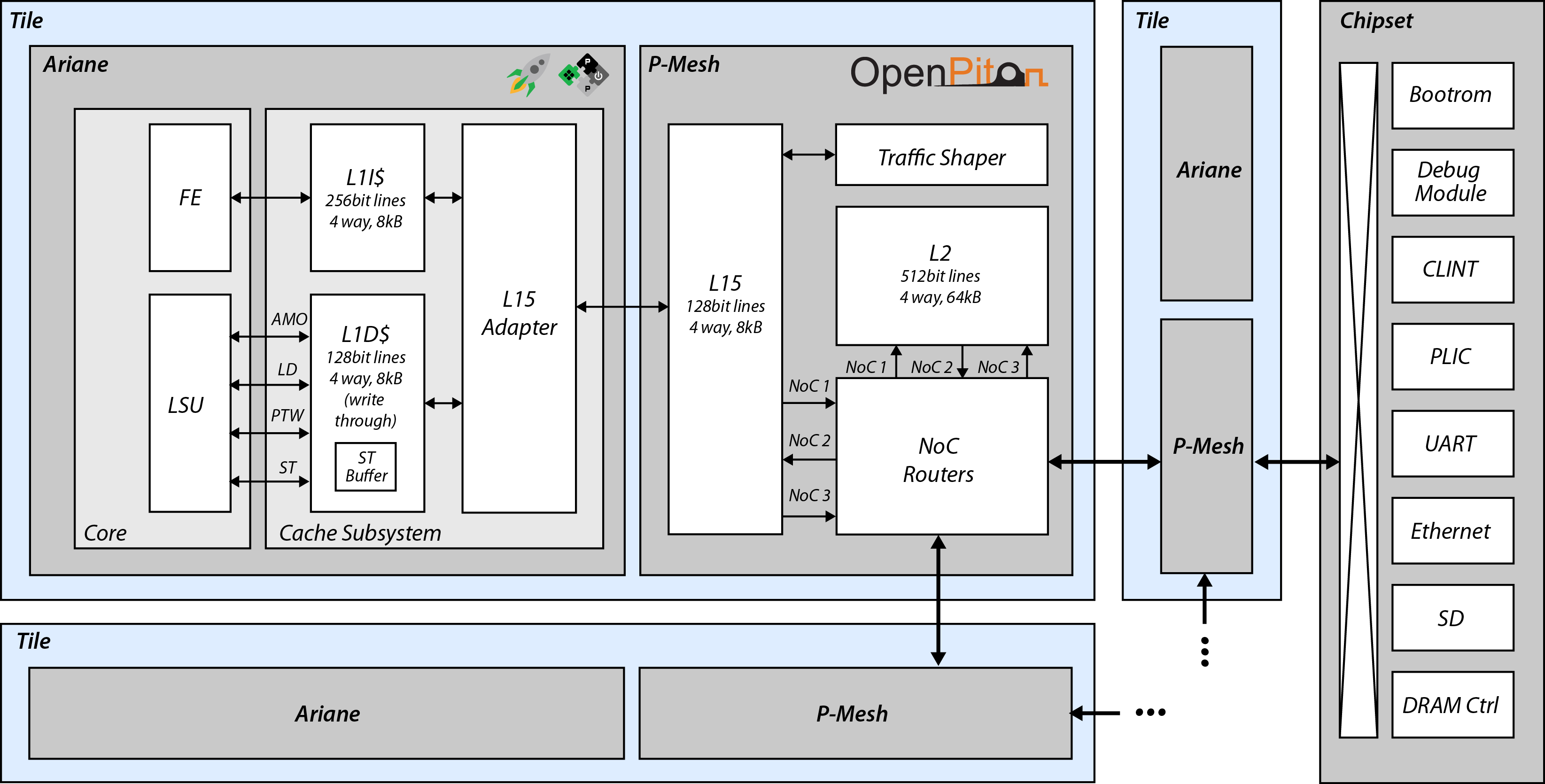
cva6仅具有L1Cache,但结合Princeton开源的OpenPiton,可以拓展L2Cache,下图是对应的逻辑简图
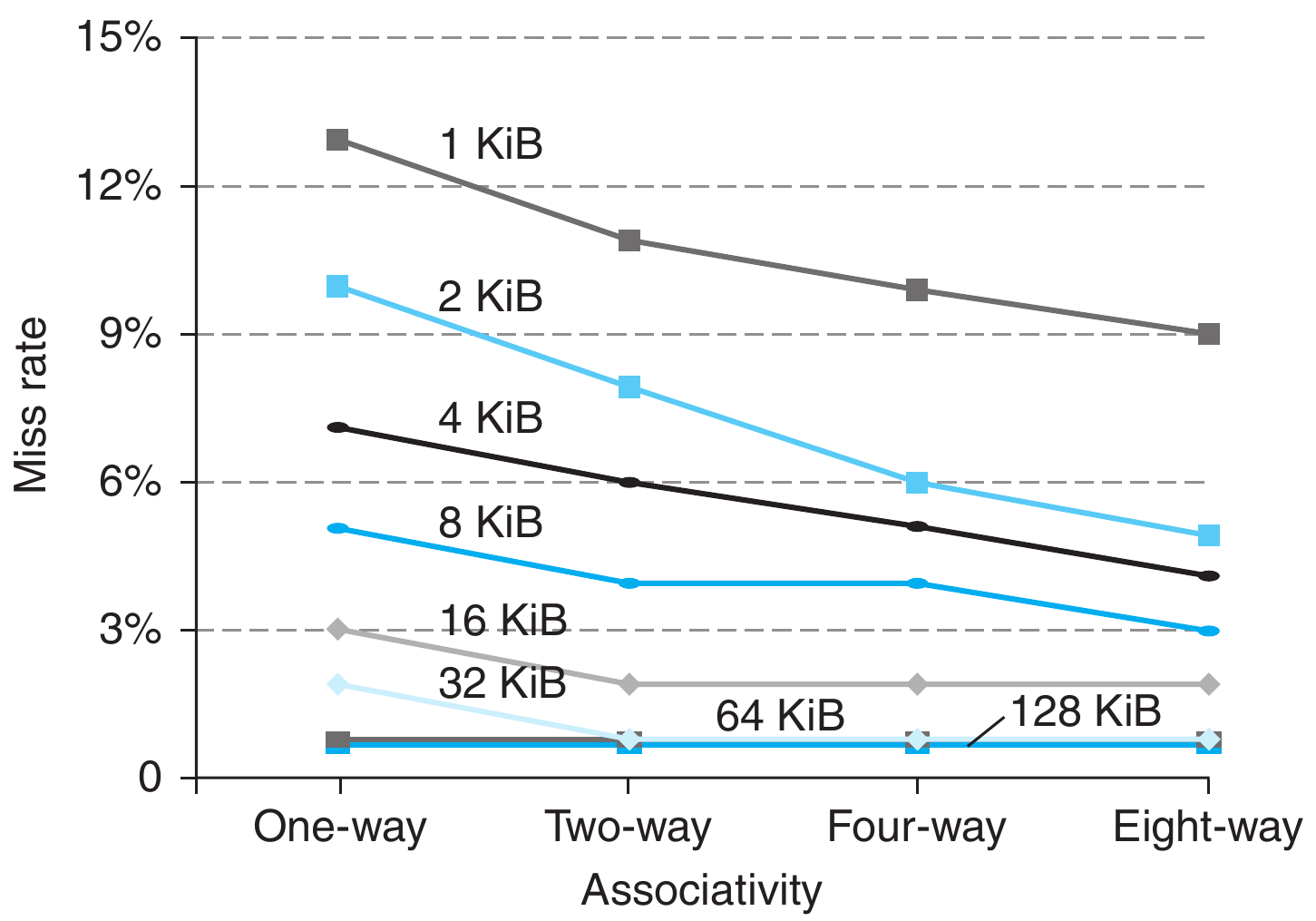
这里多说下,cache size 与 associativity 对 cache miss rate的影响如下图所示,可以有个大概的认知:cache容量越大miss的概率越小,提高相连度可以有效的改善miss rate-好像是废话hhh。
指令译码阶段-Instruction Decode
指令译码是处理器后端的第一个流水阶段。该阶段的主要目标是提取IF阶段的获得的指令,对其进行解码,并将其交给发布阶段。指令译码器的设计主要是依据如下的RISC-V指令格式,然后利用组合逻辑对对应格式的指令使用与之匹配的译码方案。

一条指令li ra,15解码使用的代码如下
// --------------------------
// Reg-Reg Operations
// --------------------------
riscv::OpcodeOp: begin
// --------------------------------------------
// Vectorial Floating-Point Reg-Reg Operations
// --------------------------------------------
if (instr.rvftype.funct2 == 2'b10) begin // Prefix 10 for all Xfvec ops
....
end
// ---------------------------
// Integer Reg-Reg Operations
// ---------------------------
end else begin
instruction_o.fu = (instr.rtype.funct7 == 7'b000_0001) ? MULT : ALU;
instruction_o.rs1 = instr.rtype.rs1;
instruction_o.rs2 = instr.rtype.rs2;
instruction_o.rd = instr.rtype.rd;
unique case ({instr.rtype.funct7, instr.rtype.funct3})
{7'b000_0000, 3'b000}: instruction_o.op = ariane_pkg::ADD; // Add
{7'b010_0000, 3'b000}: instruction_o.op = ariane_pkg::SUB; // Sub
{7'b000_0000, 3'b010}: instruction_o.op = ariane_pkg::SLTS; // Set Lower Than
{7'b000_0000, 3'b011}: instruction_o.op = ariane_pkg::SLTU; // Set Lower Than Unsigned
{7'b000_0000, 3'b100}: instruction_o.op = ariane_pkg::XORL; // Xor
{7'b000_0000, 3'b110}: instruction_o.op = ariane_pkg::ORL; // Or
{7'b000_0000, 3'b111}: instruction_o.op = ariane_pkg::ANDL; // And
{7'b000_0000, 3'b001}: instruction_o.op = ariane_pkg::SLL; // Shift Left Logical
{7'b000_0000, 3'b101}: instruction_o.op = ariane_pkg::SRL; // Shift Right Logical
{7'b010_0000, 3'b101}: instruction_o.op = ariane_pkg::SRA; // Shift Right Arithmetic
// Multiplications
{7'b000_0001, 3'b000}: instruction_o.op = ariane_pkg::MUL;
{7'b000_0001, 3'b001}: instruction_o.op = ariane_pkg::MULH;
{7'b000_0001, 3'b010}: instruction_o.op = ariane_pkg::MULHSU;
{7'b000_0001, 3'b011}: instruction_o.op = ariane_pkg::MULHU;
{7'b000_0001, 3'b100}: instruction_o.op = ariane_pkg::DIV;
{7'b000_0001, 3'b101}: instruction_o.op = ariane_pkg::DIVU;
{7'b000_0001, 3'b110}: instruction_o.op = ariane_pkg::REM;
{7'b000_0001, 3'b111}: instruction_o.op = ariane_pkg::REMU;
default: begin
illegal_instr = 1'b1;
end
endcase
end
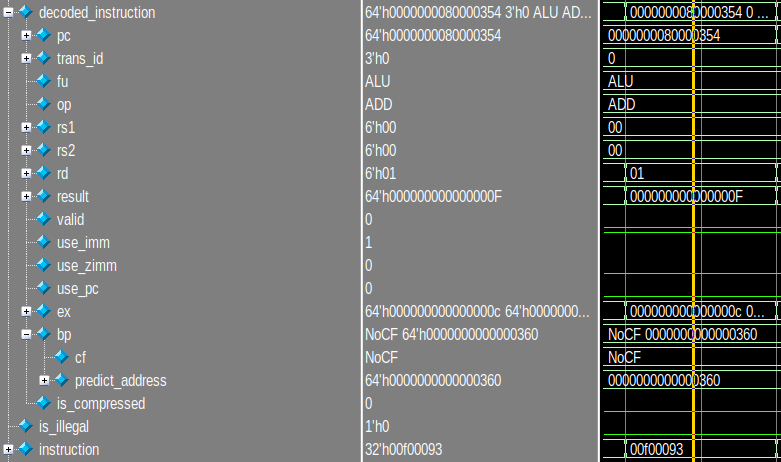
end该指令解码后的结构体示例如下, 你是否可以把解码内容与相应的汇编编码对应起来呢?
注:本阶段也包含对压缩指令的支持,但本文暂时忽略。
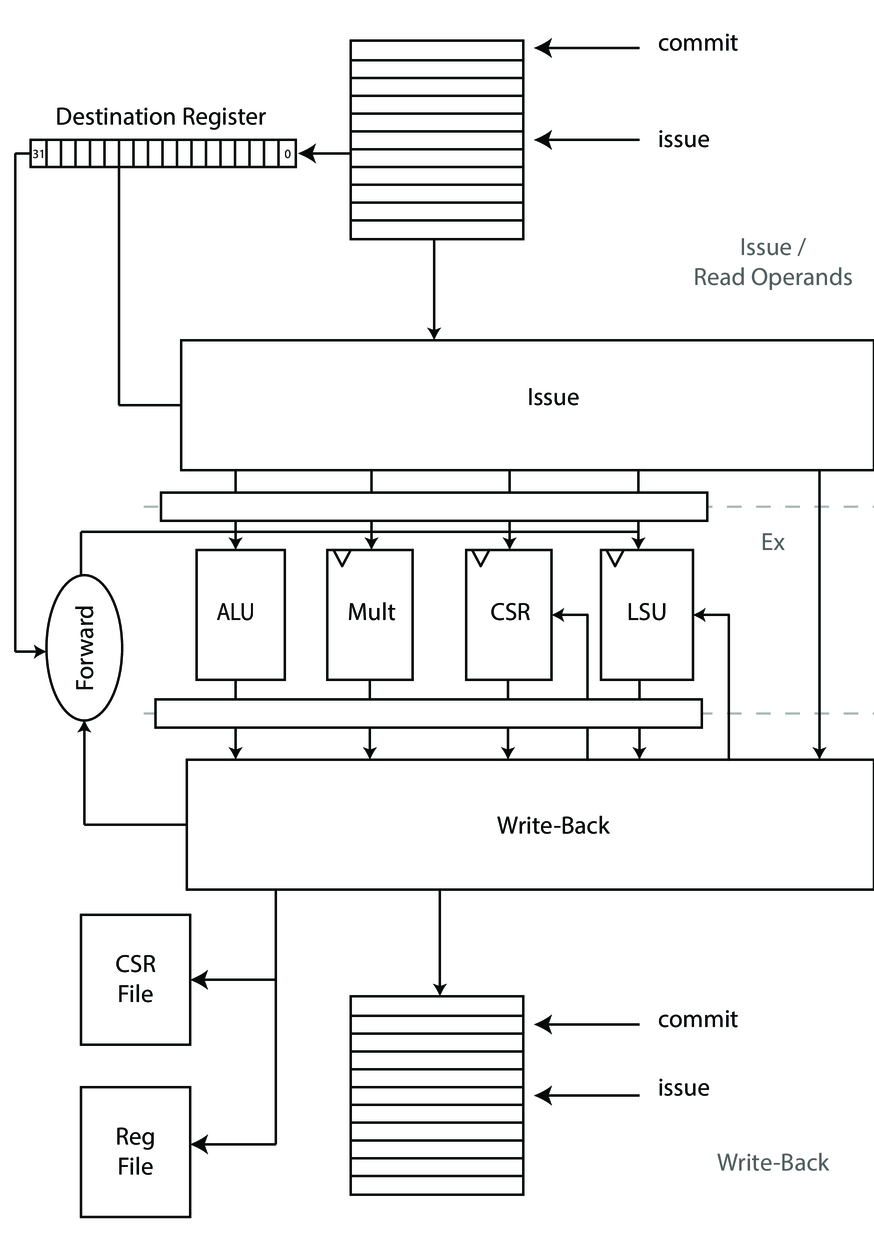
指令发射阶段-Issue
指令发射阶段的核心是利用Scoreboard来实现流水线的动态调度。Scoreboard技术在拥有足够的计算单元以及不存在数据冒险时,允许指令乱序执行,但cva6目前仅支持顺序发射、顺序执行、乱序写回、顺序派遣,因此仅存在三种数据冒险中的两种:真相关RAW、输出相关WAW。由于cva6是顺序发射与顺序执行的,所以反相关WAR这种数据冒险并不可能存在。
一条指令的执行可以大概分为4个部分,其分别是
- issue
- 该阶段会检测指令需要读取写入哪些寄存器,即检测WAW与RAW这两种数据冒险,存在冒险时阻塞发射;
- 该阶段也检测各个执行单元的状态,当需要的功能单元正忙时阻塞发射。
- read operands
- 当指令issue后,不会存在RAW这种真相关的数据冒险,因此按照指令的需求,读取execute阶段所需的各个操作数,准备进行计算;
- 本阶段结合Scoreboard运用了转发技术,提高流水线效率;
- 本阶段与issue阶段处于同一个指令周期,仅仅是概念上划分为两个阶段。
- execute
- 计算单元接收到操作数之后开始执行,结果准备就绪后通知Scoreboard已经完成执行。
- write-back
- 因顺序发射的顺序执行特性,故不存在WAR这种反相关的数据冒险,可以乱序写回。
这里放个官方的框架图作为本小节的收尾(本图与主线代码有所差异)
指令执行阶段-Execute
指令执行阶段封装了所有必须的功能模块FUs,每个FUs之间没有依赖,独立执行,与发射阶段通过握手进行通信。
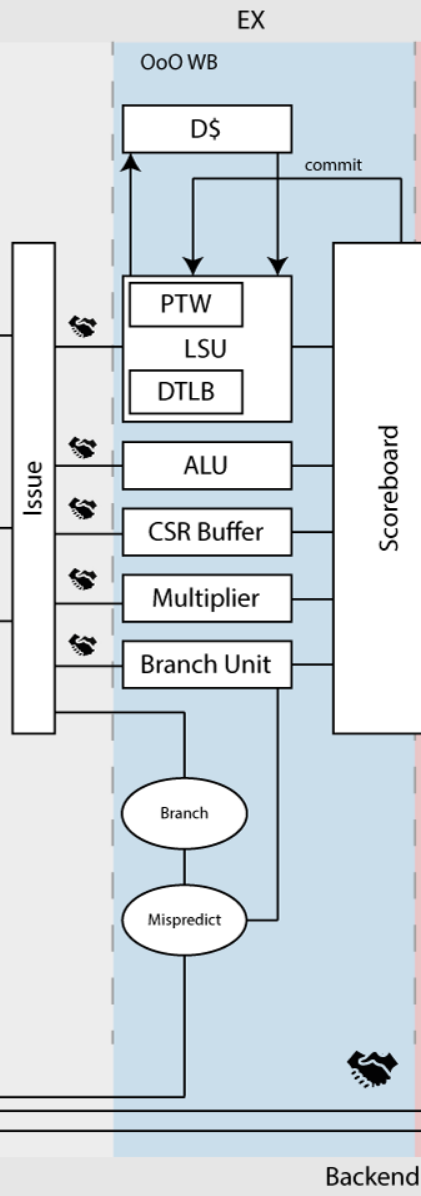
功能模块FUs主要包含
- ALU
- 算数逻辑单元ALU可以执行32与64bit加法、减法、移位、比较等计算的模块,一个周期内可完成计算。
- Branch Unit
- 分支单元管理条件分支与无条件分支,评估计算Front阶段的预测是否正确,并予以纠正。
- CSR Buffer
- CSR缓冲区的功能是缓存将要读取/写入的CSR寄存器地址。
- Multiplier
- 乘法器单元包含所需的乘法与串行除法计算单元。
- FPU
- 支持浮点计算指令
- Load Store Unit
- 加载储存单元主要服务于数据的加载与存储,但因cva6的多层级缓存与虚拟地址访存特性,需要数据转换后备缓冲区DTLB、硬件页表遍历器PTW、内存管理单元MMU等模块。
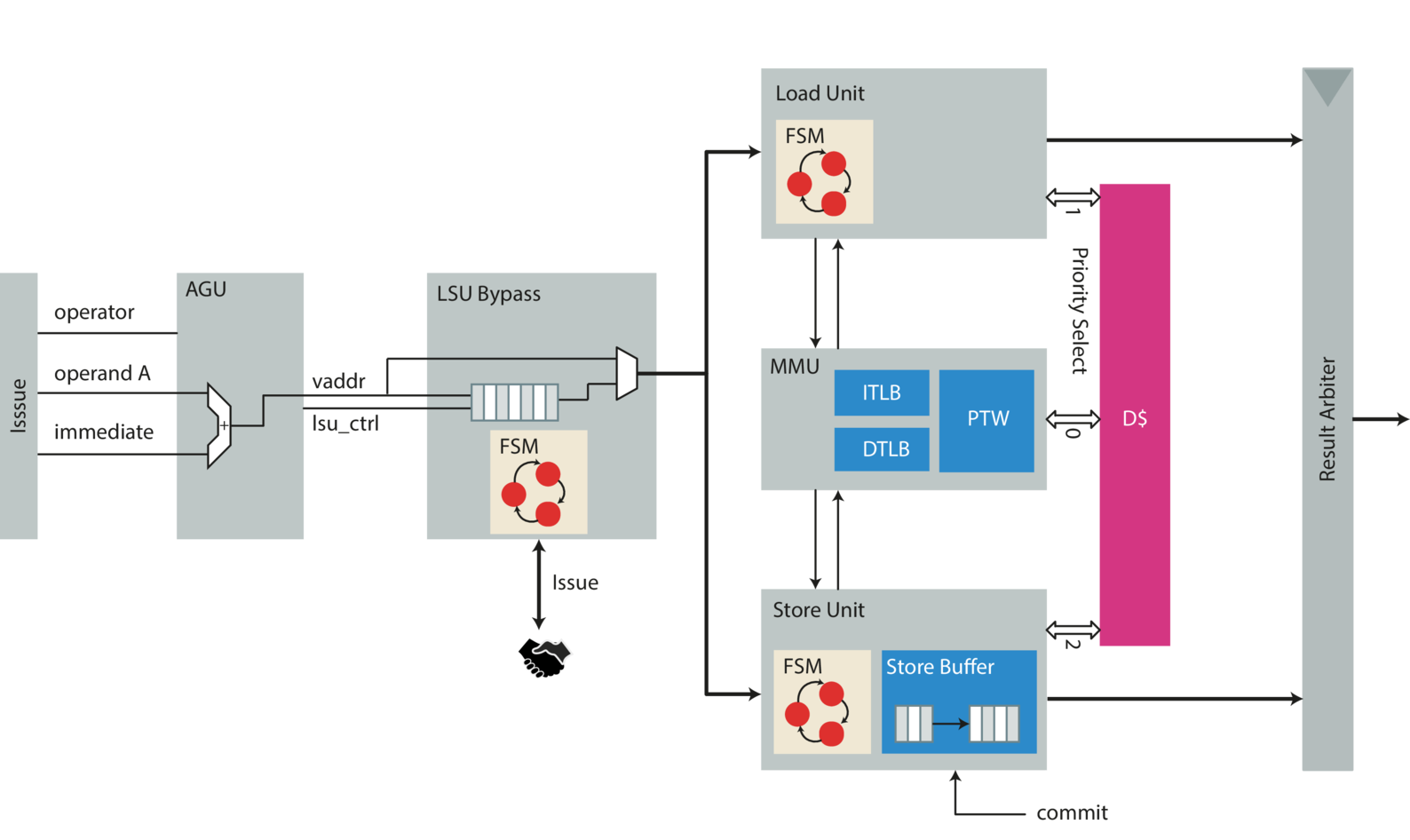
指令提交阶段-Commit
提交阶段是cva6的6级流水线的最后一个阶段,功能主要是写CSR寄存器、提交存储以及寄存器的回写。